
OLTP与OLAP
什么是 OLTP
- 全称: Online Transaction Processing(联机事务处理系统)
- 特点:
- 专注于事务处理
- 进行数据的增删改查操作
- 典型代表: MySQL、Oracle
- 用于网站和系统应用的后端数据库
- 存储业务数据(如下单、支付、注册信息)
- 支持事务操作,响应时间要求高
- 数据量相对较少
OLTP 的问题
- 当数据量达到 TB 或 PB 级别时,传统的 MySQL 性能不足
- 数据分析场景需要全盘扫描统计,不适合 OLTP
什么是 OLAP
- 全称: Online Analytical Processing(联机分析处理)
- 特点:
- 专注于复杂分析操作
- 更侧重于决策支持
- 典型代表: ClickHouse、Doris、StarRocks
- 数据量通常为 TB 级别
- 不擅长修改操作,数据一致性要求低
ClickHouse 数据库介绍
- 简介:
- 是俄罗斯的Yandex于2016年开源的列式存储数据库
- 使用c++语言编写
- 类型: OLAP 数据库
- 特点:
- 实时数据仓库,在线分析处理查询
- 支持标准 SQL 语句(如 INSERT、SELECT),实时生成分析数据报告
- 提供高级查询功能(复合聚合函数、窗口函数、跨表查询)
- 支持列式存储、数据分区和线程并行
列式存储 vs 行式存储
- 行式存储:
- 将整行数据存储为一个整体
- 列式存储:
- 将每一列作为一个数据块存储
- 优势: 更高效的统计查询、数据压缩效果好
数据分区和线程并行
- 数据分区:
- 按业务逻辑将数据分类,便于查询管理
- 示例: 按日期分区
- 线程并行:
- 多个 CPU 核心并行查询不同分区
- 优势: 降低查询延迟,利用 CPU 资源
支持丰富的表引擎
- 表引擎:
- 决定数据存储方式和位置
- 支持查询类型和并发访问
- 常用表引擎:
- MergeTree(支持分区和 TTL)
- 日志引擎(快速写入小数据)
- 集成引擎(实时接入其他数据源)
ClickHouse 的缺点
- 由于单条查询使用多核cpu,不支持高并发请求
- 对 UPDATE 和 DELETE 操作支持较差
- 单个插入性能较低,建议批量插入
- 吃硬件,一般物理机安装,单独安装不和业务混部
ClickHouse 的适用场景
- 适用于数据量大且需要分析的场景
- 适合存储已经处理过的大宽表,进行分析,读取大量列中的少量列
- 不适合高并发请求、频繁更新和删除的场景
ClickHouse安装
安装准备
- 防火墙设置:关闭防火墙以避免影响安装
- 实际工作中需根据需要配置IP和端口限制
- Linux系统文件限制,取消文件限制:否则影响ch性能
- 使用ulimit -a命令查看系统限制
- 关注的主要参数:
- 打开的文件数
- 用户最大进程数
- 修改配置文件/etc/security/limits.conf
没修改前: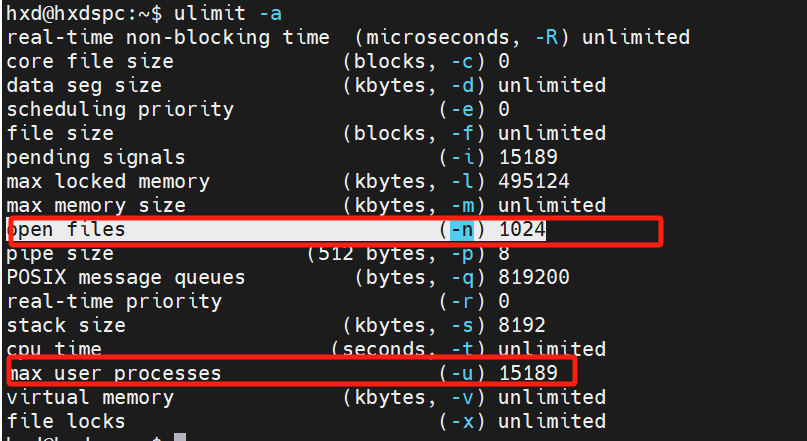
修改: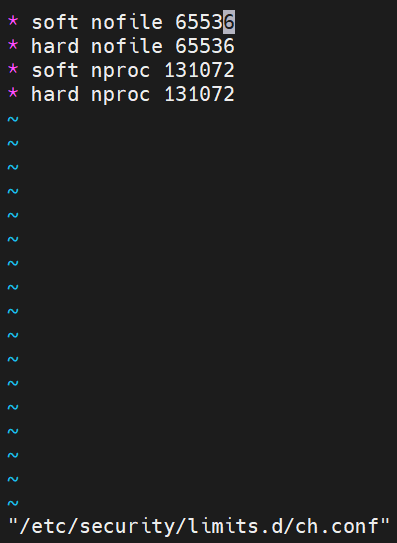
修改后: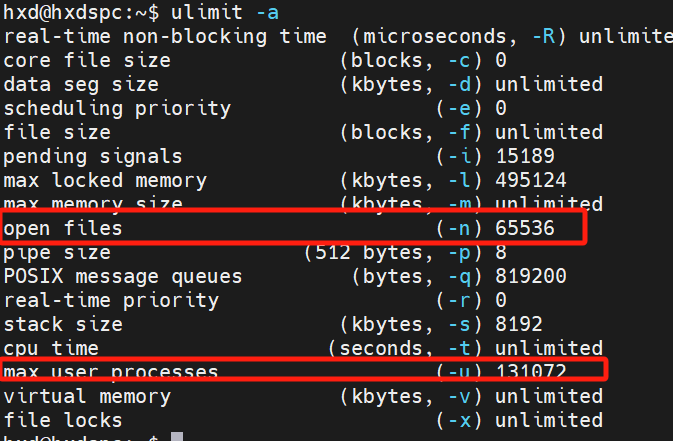
- 解释配置项:
- 用户与用户组的设置
- 软限制(soft)与硬限制(hard)的区别
- 打开文件数(number of open files)与进程数(number of processes)
- 安装依赖
linux安装由运维协助,这里不展开记录,下面直接通过docker安装(生产环境不要使用docker,这里只为了学习原理和使用,并非安装所以简化安装)
参考
https://clickhouse.com/docs/install#from-docker-image
安装
linux安装由运维协助,这里不展开记录,下面直接通过docker安装(生产环境不要使用docker,这里只为了学习原理和使用,并非安装所以简化安装)
1 | docker pull yandex/clickhouse-server:21.7.3.14 |
核心目录: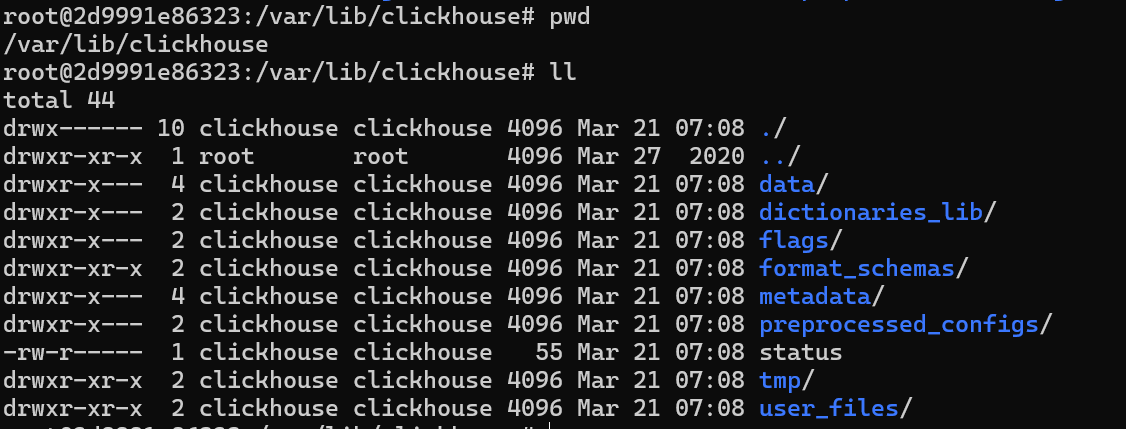
- 数据在 data目录
- 表结构信息在 metadata目录
Clickhouse数据类型
整形数值
- Int8, Int16, Int32, Int64:
- Int8: 8位(-128 到 127)
- Int16: 16位(-32768 到 32767)
- Int32: 32位(-2147483648 到 2147483647)
- Int64: 64位(-9223372036854775808 到 9223372036854775807)
- 与Java类型类比
- int8对应byte
- int16对应short
- int32对应int
- int64对应long
- 无符号整型:
- UInt8: 0 到 255
- UInt16: 0 到 65535
- UInt32: 0 到 4294967295
- UInt64: 0 到 18446744073709551615
浮点型
浮点型的分类
- Float32: 32位(4字节)
- Float64: 64位(8字节)
精度问题
- 浮点型存储可能会导致精度丢失,尤其在处理货币时应避免使用。
布尔类型
- 使用uint8表示布尔值
- 0表示false
- 1表示true
Decimal类型
- Decimal(p, s):
- p: 总位数
- s: 小数位数
- 类型示例
- decimal(32, 5) 整数小数一共9位, 小数后5位
- decimal(64, 5), 整数小数一共18位, 小数后5位
- decimal(128, 5) 整数小数一共38位, 小数后5位
- Decimal(p, s):
字符串类型
- String: 可变长度字符串。
- FixedString(n): 固定长度字符串,不足部分用空字节填充。
枚举类型
- 定义和使用枚举, Enum8,Enum16
- 插入和查询枚举值的示例
1
2
3
4
5
6
7
8
9
10CREATE TABLE t_enum (
x Enum8('hello' = 1, 'world' = 2)
) ENGINE = TinyLog;
INSERT INTO t_enum VALUES ('hello'),('world'),('hello');
SELECT * FROM t_enum;
# 转换查询
SELECT CAST(x, 'Int8') FROM t_enum; - 插入未知类型会报错
时间类型
- Date: 仅包含年月日。
- DateTime: 包含年月日时分秒。
- DateTime64: 包含亚秒(毫秒)。
数组类型
- mergeTree表中不能存储多维数组
- 使用 Array 表示,支持单层数组。
- 例子:Array(UInt8) 表示存储无符号8位整型的数组。
1
2
3
4
5
6
7
8
9
10
11
12SELECT array(1,2) AS x, toTypeName(x);
2d9991e86323 :) SELECT array(1,2) AS x, toTypeName(x);
SELECT
[1, 2] AS x,
toTypeName(x)
┌─x─────┬─toTypeName([1, 2])─┐
│ [1,2] │ Array(UInt8) │
└───────┴────────────────────┘
1 rows in set. Elapsed: 0.013 sec.
其他数据类型
介绍其他常用数据类型
可查阅ClickHouse官网获取更多信息
https://clickhouse.com/docs/zh/sql-reference/data-types空值处理
ClickHouse中的空值存储方式
建议使用无意义的数字或字符表示空值, 避免使用NULL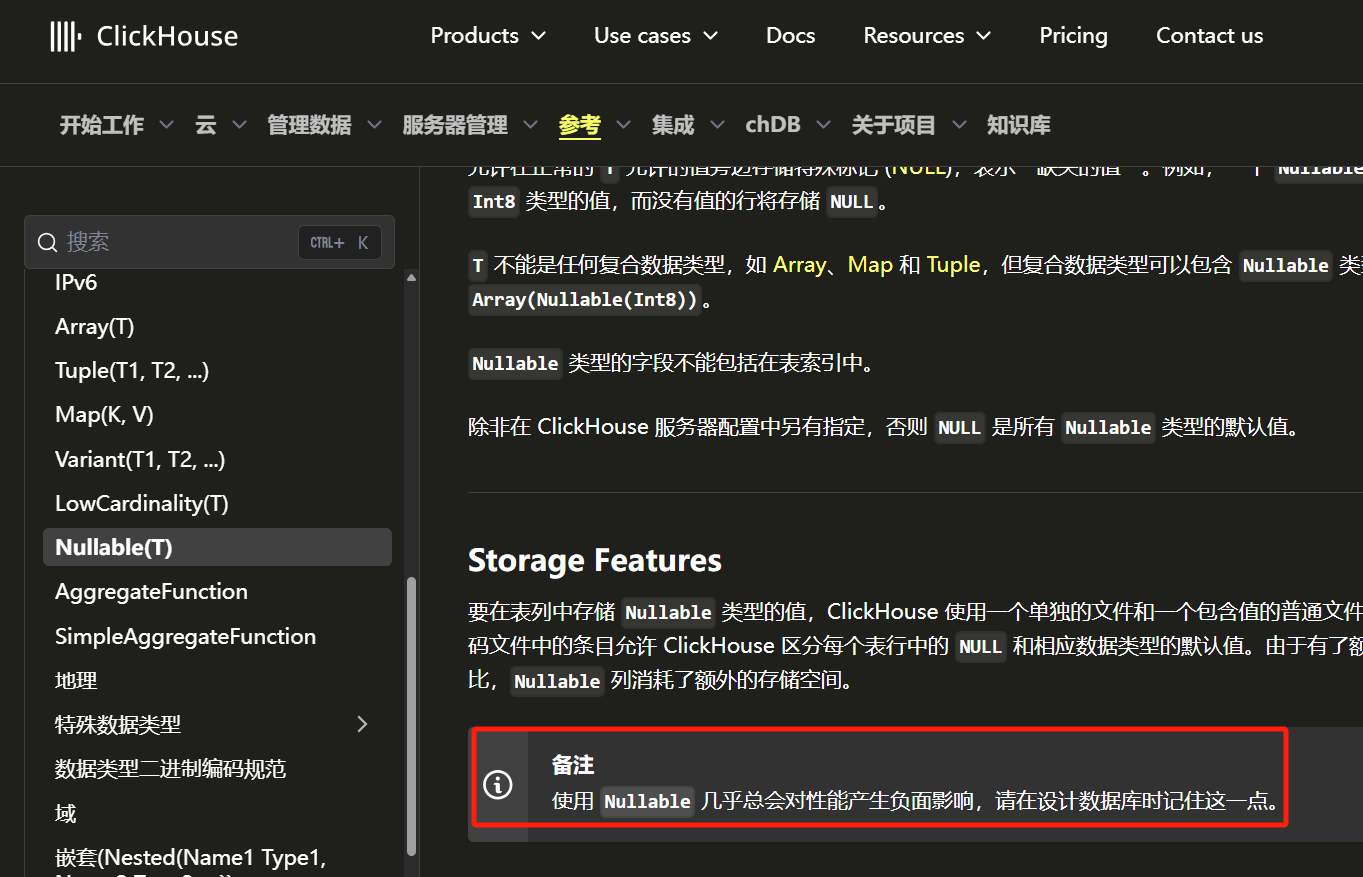
比如可以用-1,无意义得值,字符串可以搞空串或者null等
Clickhouse表引擎
概述
- 表引擎的定义:类似于MySQL中的InnoDB和MyISAM,不同引擎具有不同的功能和作用。
- 表引擎的作用:
- 决定数据的存储方式和位置。
- 指定如何读写数据。
ClickHouse表引擎的特点
- 存储方式和位置
- 数据一般存储在本地磁盘上。
- ClickHouse不依赖于Hadoop或HDFS计算资源。
- 默认配置路径:/var/lib/clickhouse/data。
- 支持的查询及语法
- 不同引擎支持不同的查询语法。
- 例如,某些引擎不支持多维数组存储。
- 并发数据访问
- ClickHouse支持多线程并发查询,但并非所有引擎都支持。
- 索引支持
- 不同引擎对索引的支持程度不同,索引的目的是提高查询效率。
- 数据复制
- 某些引擎支持数据复制,而其他引擎则不支持。
- 引擎名称是大小写敏感的,采用大驼峰命名法。
表引擎TinyLog
- 属于日志家族,适合小数据量(小于100万行)。
- 特点:
- 存储在磁盘上,不支持索引。
- 无并发控制,适合简单测试。
- 做一些简单测试,生产环境肯定不会用
1
CREATE table t_tinylog(id String,name String) engine=TinyLog;
表引擎Memory
- 基于内存,性能(超过10G/s)快但数据易丢失。
- 特点:
- 不支持索引,适合小数据量测试。
- 做一些简单测试,生产环境肯定不会用
MergeTree系列
- ClickHouse的核心引擎,适合生产环境。相当于innodb之于mysql
- 包含多个变种,如ReplacingMergeTree和SummingMergeTree,具有不同功能。
参考官方文档:
https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family
集成引擎
集成外部系统,如MySQL和Kafka。
外部集成的意义:无需将数据导入ClickHouse,直接查询外部数据源。
https://clickhouse.com/docs/zh/engines/table-engines/integrations
MergeTree引擎
mergeTree家族的第一个引擎——MergeTree。
MergeTree引擎本身是一个表引擎。
介绍建表语句和嵌表语句。
参考:
https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/mergetree
建表语句
1 | CREATE TABLE t_order_mt( |
primary key是可以重复的,这和mysql不一样
order by 是必须的, primary key 不是必须的
测试数据(多执行几次,多插入一些):
1 | INSERT INTO t_order_mt (id, sku_id, total_amount, create_time) VALUES (1, 'SKU001', 100.50, '2023-01-01 10:00:00'), (1, 'SKU002', 200.75, '2023-01-01 15:30:00'), (3, 'SKU003', 50.20, '2023-03-20 09:15:00'), (4, 'SKU004', 150.00, '2023-05-10 14:45:00'), (5, 'SKU005', 300.99, '2023-05-10 11:20:00'), (6, 'SKU006', 75.55, '2023-06-30 16:50:00'); |
查询结果,分区了O(∩_∩)O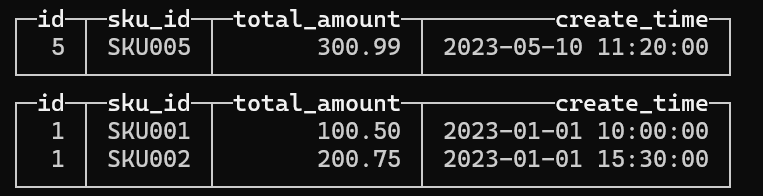
连接配置
连接ClickHouse的步骤:
使用主机名和端口(默认端口为8123)。
默认用户名为default,密码为空。
如果驱动未自动下载,需要手动添加驱动文件。
partition by 分区(可选)
不是必须的建表语句
分区的作用
主要目的是避免全表扫描。
查询语句中加入分区字段的取值,可以优化查询速度。
分区的实现方式类似于物理分隔,像是将数据分放在不同的房间。ClickHouse的分区机制
ClickHouse的分区是基于本地磁盘,而hive的分区是在HDFS上建立分区目录。
如果不写分区,默认会用一个分区,名为“all”,所有数据都在里面。并行查询
单个查询可以多线程同时执行。
每个线程处理一个分区的数据。
通常按天分区,因为这样可以避免不必要的麻烦。分区的存储
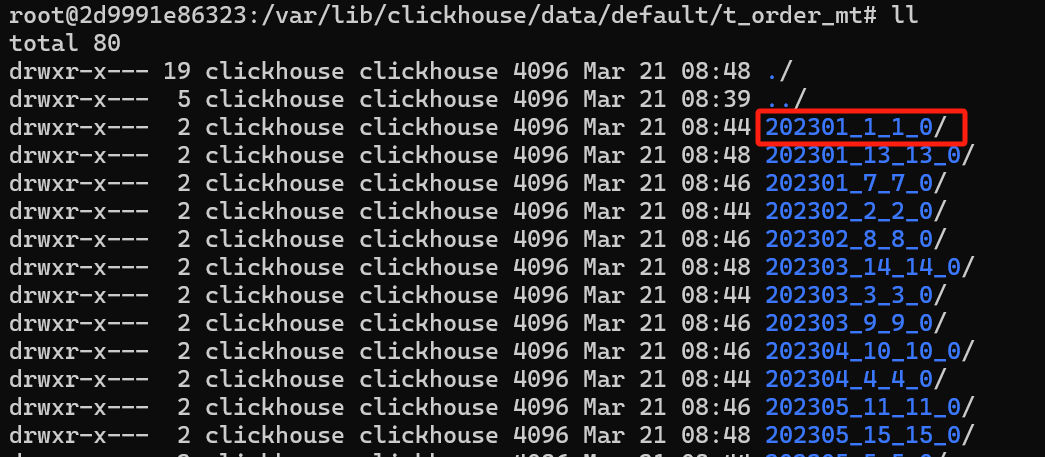
数据存储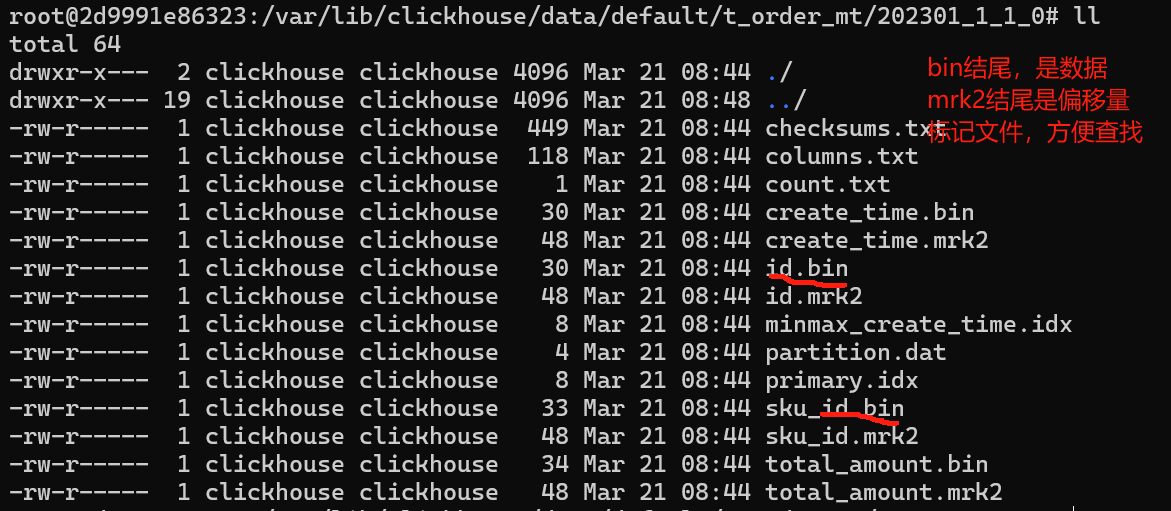
稀疏索引
索引文件采用的稀疏索引,和kafka的partition一样分区目录原理
- 分区目录如上图所示, 第一位分区键,第二位最小区块编号,第三位,最大区块编号,第四位合并层级
- 日期类型分区键,最好存日期类型,不像其他数仓,hive存字符串,这样效率高
- 其他类型分区目录,如string,float类型分区建,目录名字取hash
数据写入与分区合并
- 每次数据写入会产生一个临时分区,之后需要执行合并操作。
- 合并是定期执行的,可以手动触发。
- 手动触发指令
1
OPTIMIZE TABLE t_order_mt FINAL
- 可以加一个分区参数 合并之后,分区目录目录会变,产生合并后的目录,过期数据会自动清理,删除。
1
OPTIMIZE TABLE t_order_mt PARTITION '20230101' FINAL
primary key主键(可选)
- 提供了数据的一级索引,但不是唯一约束
主键的设定主要依据查询中的where条件。(一般加载where条件中)
index granularity

直接翻译就是索引粒度,指在稀疏索引中两个相邻索引对应的间隔,Clickhouse中mergeTree默认是 8192,官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据。稀疏索引
索引文件采用的稀疏索引,和kafka的partition一样
要求主键必须有序所以必须要有order bt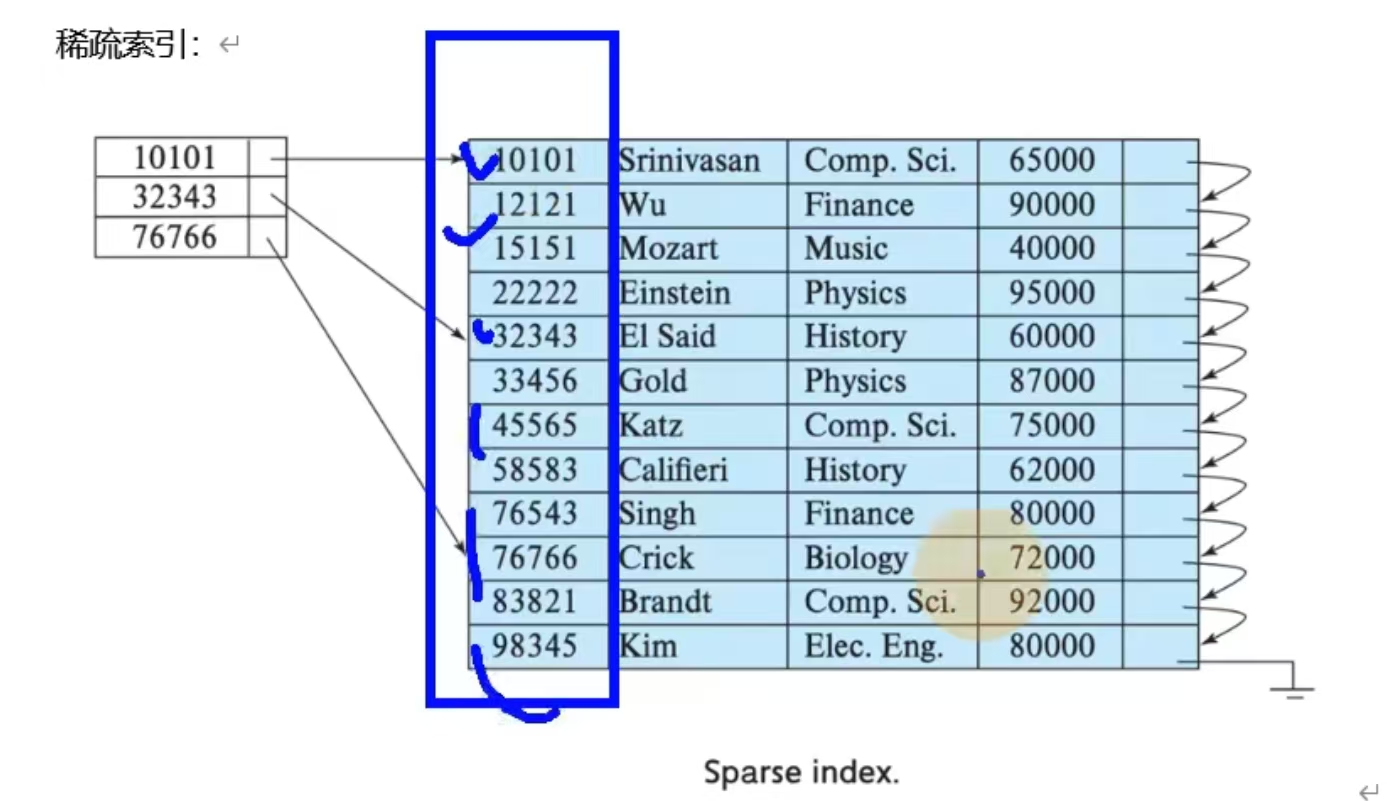
优点:数据量小,查询效率高
order by(必选)
- 分区内排序
- 必填 甚至比主键还重要, 因为要建立稀疏索引,且后面去重和汇总也要用到order by
- 可以多个字段,但必须是左前坠, 比如(id,sku_id) 要么是id ,要么是id,sku_id,不能是sku_id,id 和sku_id
二级索引
版本问题
20.1.2.4之前,官方标注是实验性的,之后是默认开启的(20年1月份版本)
之前版本可以用以下命令设置,之后版本会报错1
set allow_expreimental_data_skipping_indices=1
二级索引使用在大量重复数据的场景下
二级索引不必有序
二级索引也叫跳数索引如何使用
1
2
3
4
5
6
7
8
9
10CREATE TABLE t_order_mt2(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time DateTime,
INDEX a total_amount TYPE minmax GRANULARITY 5
) engine=MergeTree
partition by toYYYYMM(create_time)
primary key (id)
order by (id,sku_id);二级索引的类型是 minmax
minmax 是最小最大值索引,粒度是5, 也就是5个数据算一个区间, 然后取最小值和最大值。
1 | INSERT INTO t_order_mt2 (id, sku_id, total_amount, create_time) VALUES (1, 'SKU001', 100.50, '2023-01-01 10:00:00'), (1, 'SKU002', 200.75, '2023-01-01 15:30:00'), (3, 'SKU003', 50.20, '2023-03-20 09:15:00'), (4, 'SKU004', 150.00, '2023-05-10 14:45:00'), (5, 'SKU005', 300.99, '2023-05-10 11:20:00'), (6, 'SKU006', 75.55, '2023-06-30 16:50:00'); |
1 | clickhouse-client --send_logs_level=trace <<< 'select * from t_order_mt2 where total_amount > toDecimal32(900,2)' |
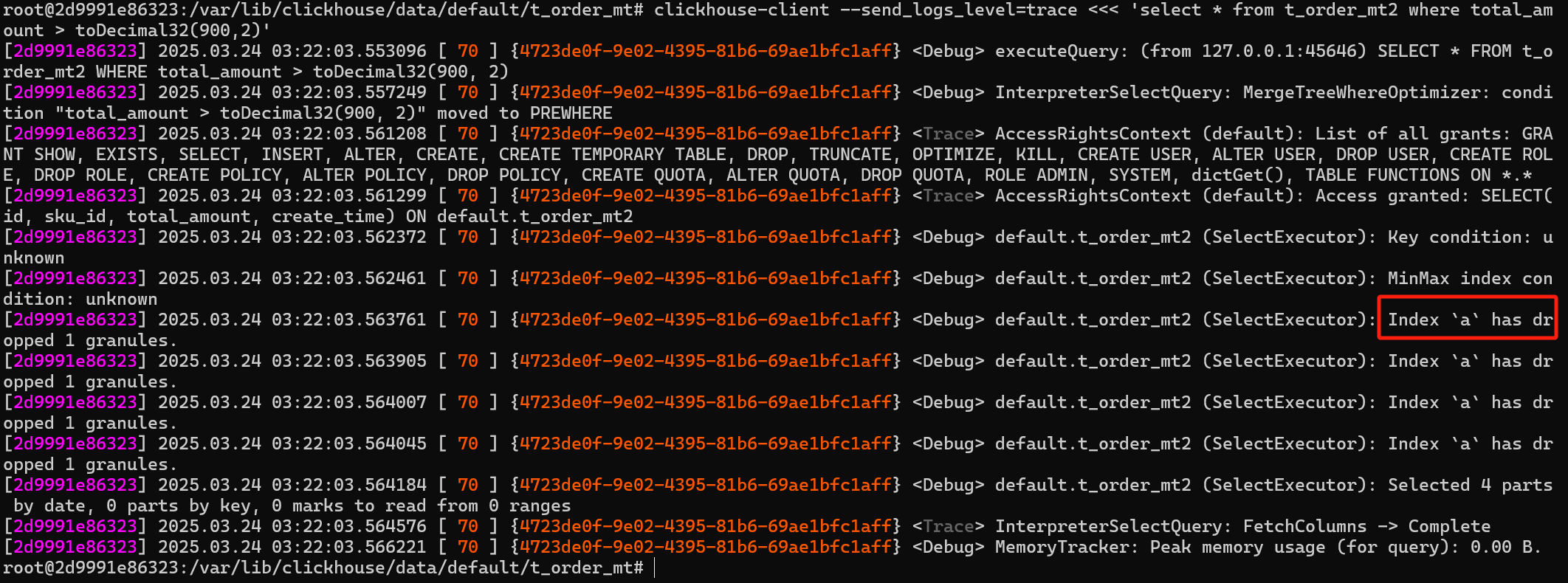
使用了二级索引
数据TTL
time to alive 数据存活时间
- 对某一列设置ttl, 数据过期之后,会自动删除
1
2
3
4
5
6
7
8
9
10CREATE TABLE t_order_mt3(
id UInt32,
sku_id String,
total_amount Decimal(16,2) TTL create_time + INTERVAL 10 SECOND,
create_time DateTime,
INDEX a total_amount TYPE minmax GRANULARITY 5
) engine=MergeTree
partition by toYYYYMM(create_time)
primary key (id)
order by (id,sku_id);
时间到期,这一列就会被删除(相当于时间到了,会启动一个合并任务,处理删除)
- 表级TTL会根据每行的create_time 字段进行过期删除
1
ALTER table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;
TTL不能使用到主键字段
参考:
https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/mergetree
ReplacingMergeTree 引擎
替换合并树
他的存储特性完全继承MergeTree, 多了一个去重功能
不是根据主键去重,而是根据order by的字段去重
去重时机
不是实时去重,只会在同一批插入(新版本)或合并的过程去重。
最终一致性,不实时一致去重范围
分区内去重,不能跨分区去重1
2
3
4
5
6
7
8
9CREATE TABLE t_order_rmt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time DateTime
) engine=ReplacingMergeTree(create_time)
partition by toYYYYMM(create_time)
parimary key (id)
order by (id,sku_id);
ReplacingMergeTree(create_time) 中create_time 表示按照order by的去重之后,保留crate_time最大的数据。
不指定,默认按照插入顺序来,保留最后插入的。
SummingMergeTree 引擎
预聚合求和合并树
分区内聚合
按照order by
1 | CREATE TABLE t_order_smt( |
以上求和total_amount,是按照gruop by id,sku_id来聚合求和的, 重要的是order_by,如果不指定total_amaount,那么会按照order by求和所有的数字列。
1 | insert into t_order_smt values (1,'sku001',100.50,'2023-01-01 10:00:00'),(1,'sku001',200.75,'2023-01-01 15:30:00'),(3,'sku003',50.20,'2023-03-20 09:15:00'),(4,'sku004',150.00,'2023-05-10 14:45:00'),(5,'sku005',300.99,'2023-05-10 11:20:00'),(6,'sku006',75.55,'2023-06-30 16:50:00'); |
结果,两条被聚合了: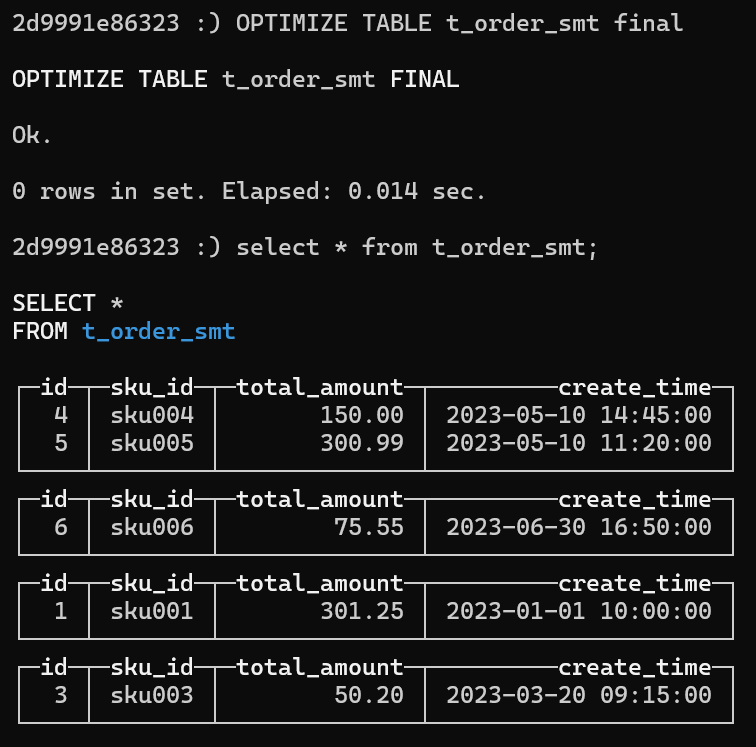
且crate_time 是最前面的一条(第一行),而不是最后一条(最大)
只有在同一批次插入时(新版本),或分片合并时才会聚合
设计聚合表时,最好设置聚合的列,否则序号之类的都会被聚合,没有意义
查询的时候,还是需要在sql里面写sum(),因为可能还没来得及聚合,体会下预聚合
Clickhouse SQL操作
insert
和mysql一样
从表到表,支持insert into xxx select
update和delete
OLAP的,不叫更新,叫做可变查询, 是ALTER的一种
不支持事务
- 物理删除
1
alter table t_order_mt delete where id = 1;
- 逻辑删除
1
alter table t_order_mt update status = 1 where id = 1;
- 恢复
1
alter table t_order_mt update status = 0 where id = 1;
这种删除操作比较重,分了两步,新增分区并发旧分区打上逻辑失效标记,直到合并的时候才会释放磁盘空间,一般这种功能不给用户,由管理员完成
实践中, 可以加_sign标记,_version版本号机制以新增的方式替代删除,缺点就是数据膨胀
查询操作
支持子查询
支持CTE Common Table Expression 公用表表达式with子句
语法支持join,但是实际上避免join,json操作无法使用缓存,所以即使是join ch也会查询两次,且占用内存,且分布式的话内存爆炸
窗口函数,目前官网表示正在试验阶段
各种函数查看官网
多维分析函数
不支持自定义函数
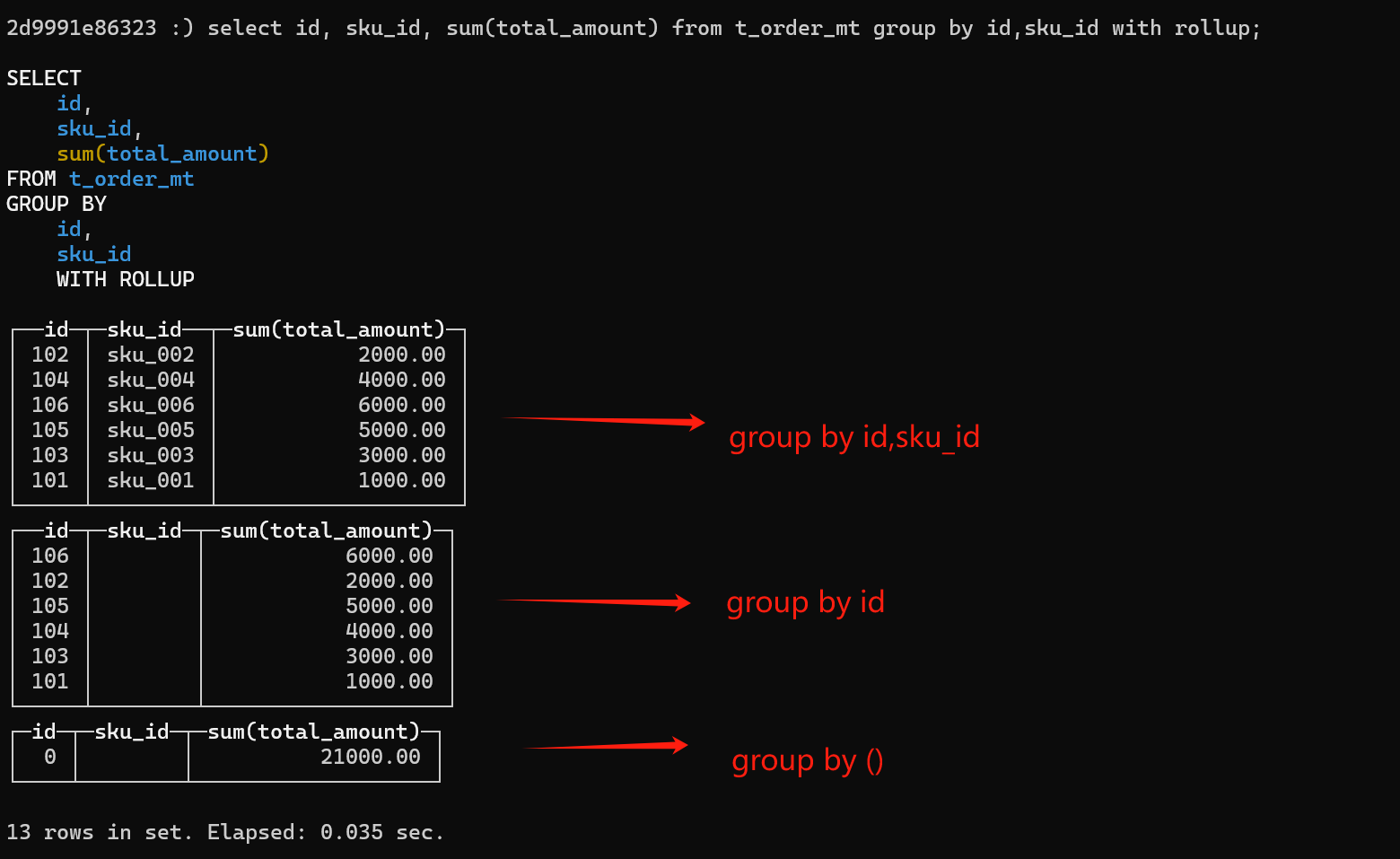
GROUP BY 增加了with rollup上卷 , with cube多维分析, with totals总计 来计算小计和总计
比如按照a,b维度分析,
上卷:
分析 group by a,b
分析 group by a
分析 group by ()
多维分析:
分析 group by a,b
分析 group by a
分析 group by b
分析 group by ()
总计分析:
分析 group by a,b
分析 group by ()
1 | alter table t_order_mt delete where 1=1; |
alter操作
和mysql基本一致
新增字段
1 | alter table tableName add column newcolname String after col1; |
修改字段类型
1 | alter table tableName modify column colname String; |
删除字段
1 | alter table tableName drop column colname; |
导出数据
1 | clickhouse-client --query "select * from t_order_mt where create_time='2024-01-01 12:00:00'" --output_format_csv_separator="\t" --output_format_csv_with_names --output_format_csv_with_names_and_types > /tmp/t_order_mt.csv |
更多格式
参考官网
副本
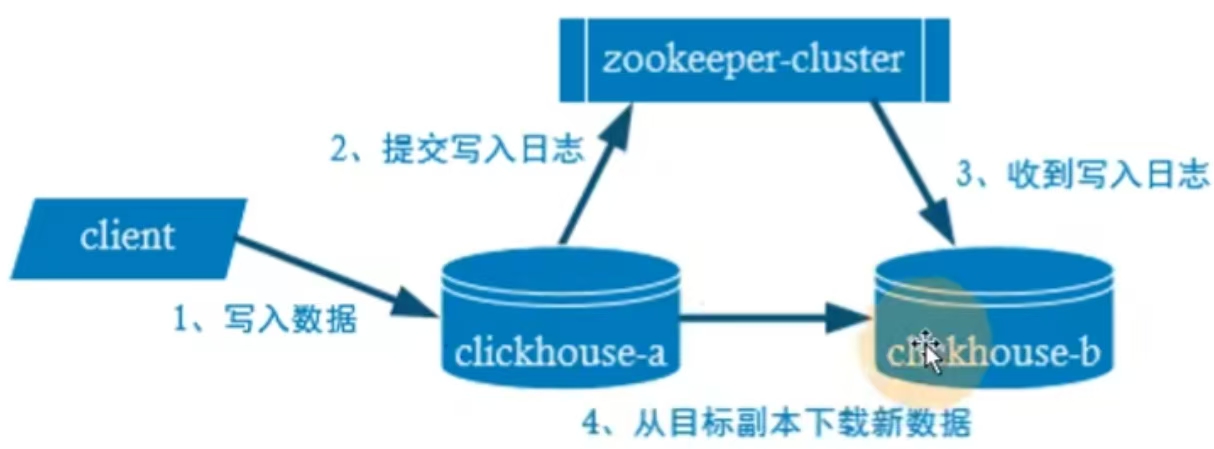
互为副本, 平权
注意点:副本的表引擎都要加Replicated
例如:
- ReplicatedMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedSummingMergeTree
其他可参考官方文档
分片集群
clickhouse支持数据分片到不同机器上存储
- 集群写入流程(3分片2副本共6个节点)
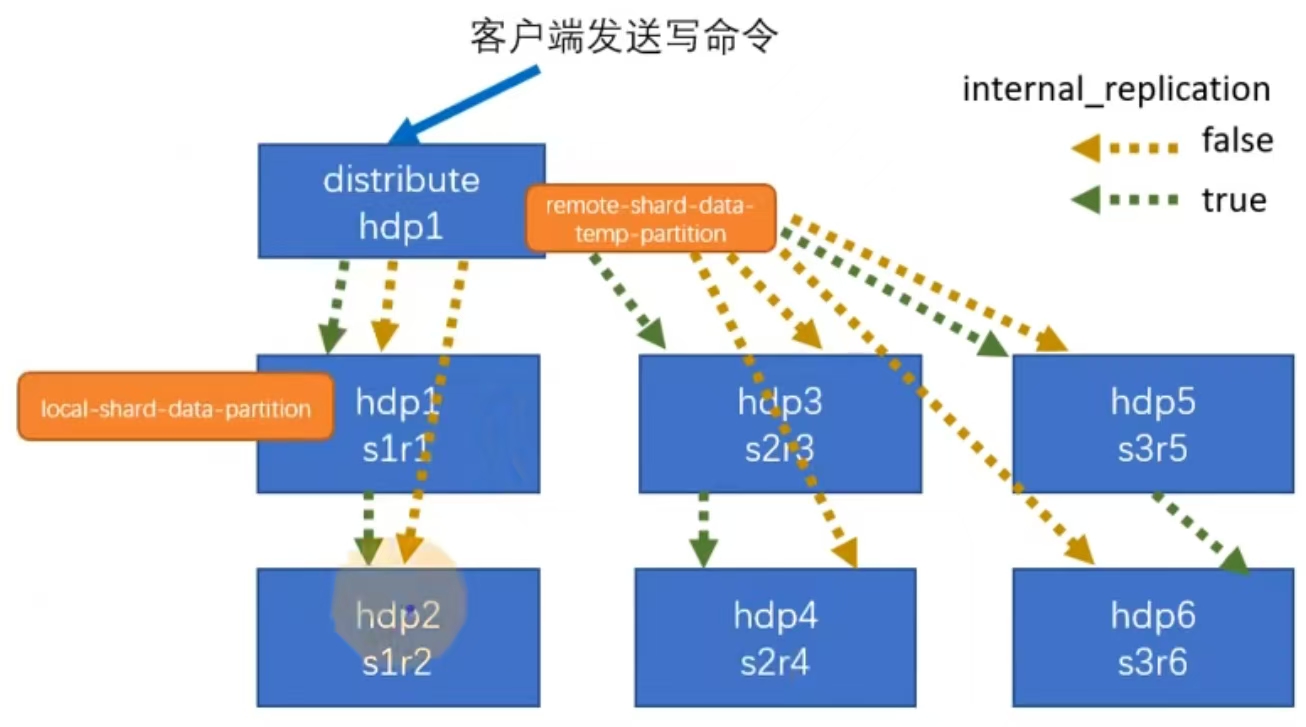
s1 s2 s3 三个分片,
r1 r2 每个分片两个副本
参数 internal_replication 内部副本参数
false得话,非内部同步,如图黄色
true得话,内部同步(生产一般要打开true),如图绿色
- 集群读取流程
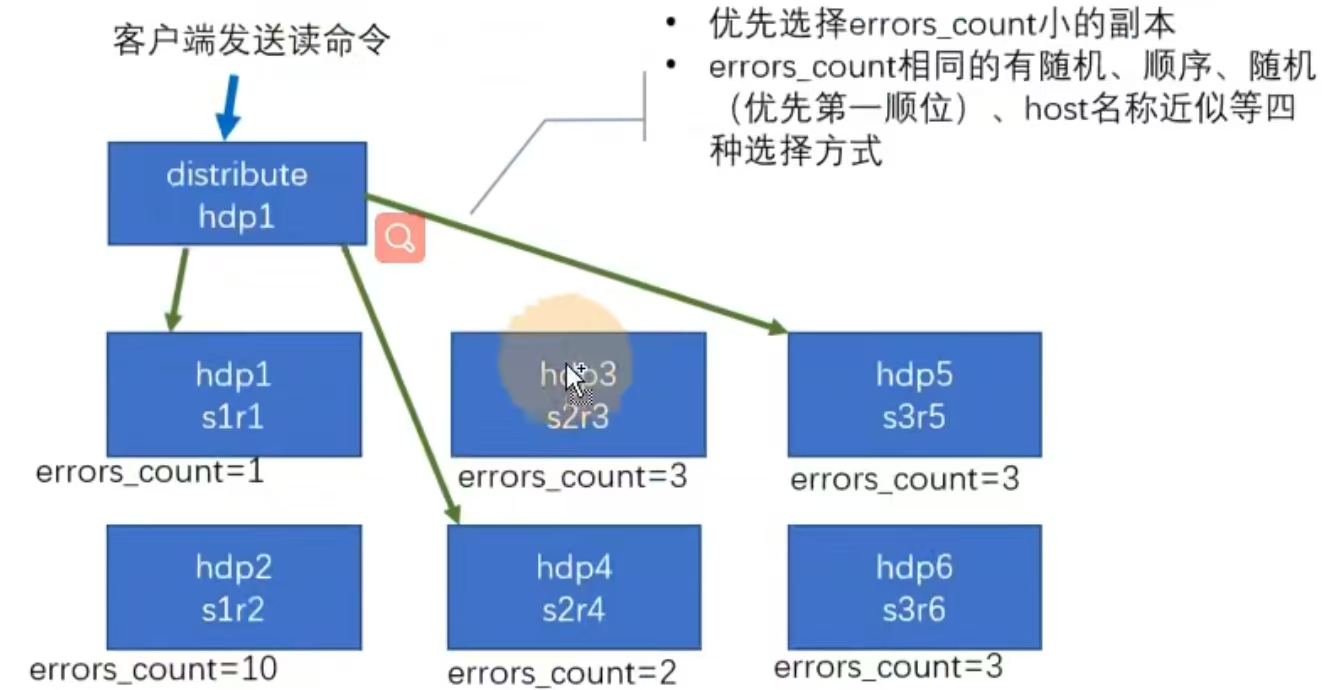
- 优先选择errors_count小得副本
- errors_count相同,有随机,顺序,随机(优先第一顺位)host名称近似等四种选择方式
- 集群建表
创建本地表:参数含义:1
2
3
4
5
6
7
8
9CREATE TABLE st_order_mt on cluster gmall_cluster (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time DateTime
)engine=RepilicatedMergeTree('/clickhouse/tables/{shard}/st_order_1109', '{replica}')
patition by toYYYYMMDD(create_time)
primary key(id)
order by(id,sku_id);
集群名, 集群配置里面得宏定义
本地表得意思是集群每个节点都创建一个表
创建分布式表:
1 | CREATE TABLE st_order_mt_all on cluster gmall_cluster ( |
参数含义:
集群名称,库名,本地表名,分片键
统领本地表,有点视图得意思
- 插入数据
插得是分布式表,实际上存在每一张表1
INSERT INTO st_order_mt_all values()
Clickhouse执行计划
官方推荐独立部署,128G硬盘 100G内存,32线程内核
参考官文档:
https://clickhouse.com/docs/zh/sql-reference/statements/explain
语法
1 | EXPLAIN [AST | SYNTAX | QUERY TREE | PLAN | PIPELINE | ESTIMATE | TABLE OVERRIDE] [setting = value, ...] |
EXPLAIN 类型:
- AST — 抽象语法树。
- SYNTAX — 经 AST 级别优化后的查询文本。
- QUERY TREE — 经查询树级别优化后的查询树。
- PLAN — 查询执行计划。 (默认)
- PIPELINE — 查询执行流水线。
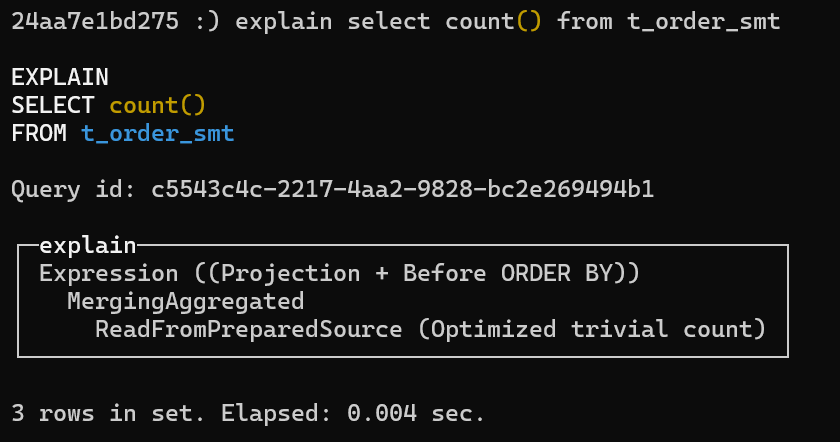
以上实例说明该查询走了预处理文件,也就是直接读的文件资源,速度比较快。
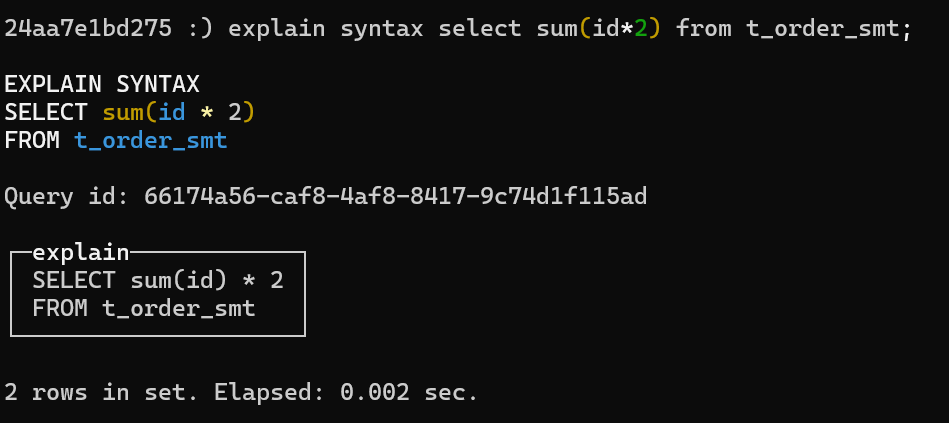
以上示例,对查询做了优化
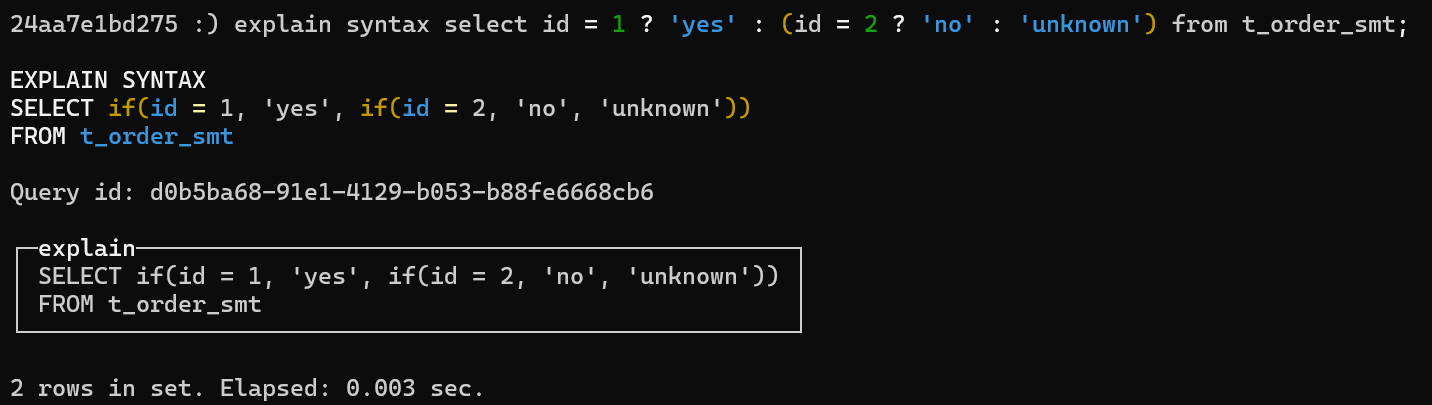
以上对三元嵌套查询做了优化
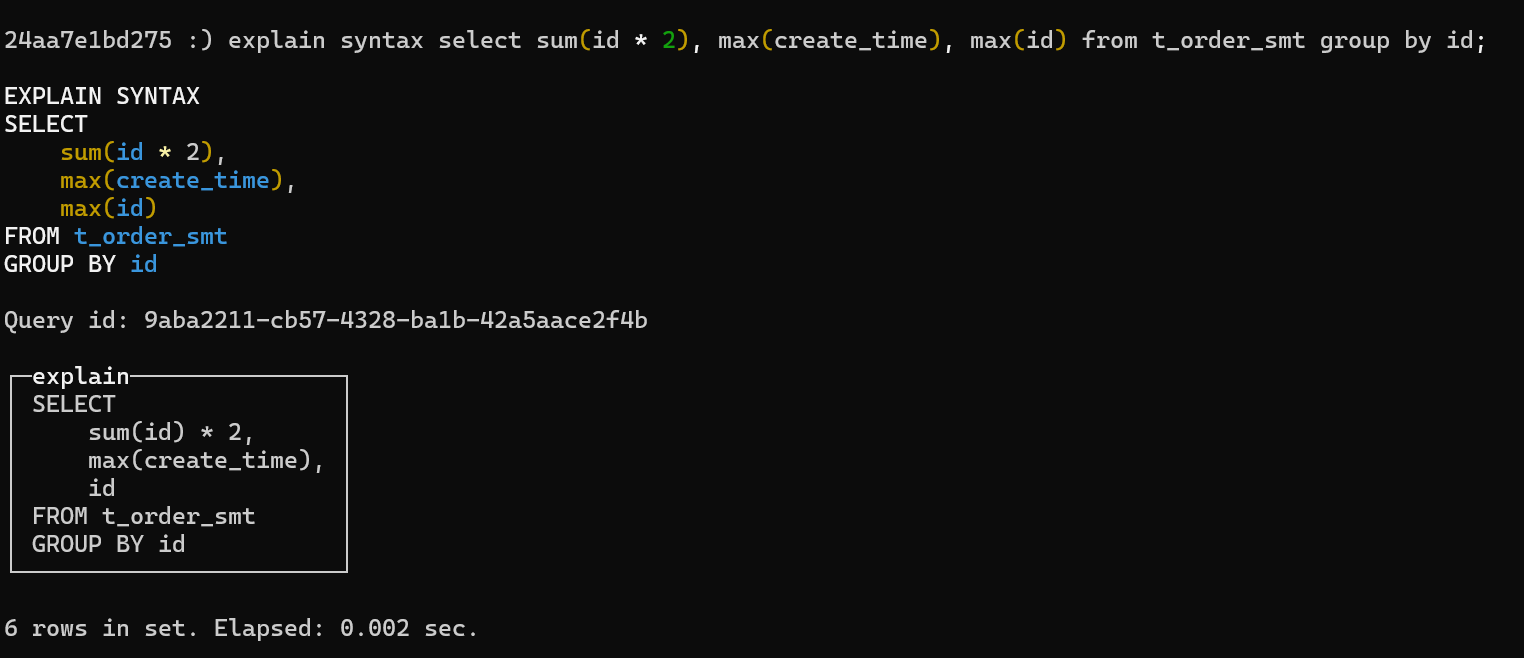
以上对函数查询做了优化
提升查询性能总结
选择合适的表引擎, mergeTree是ch常见的引擎,但不意味着mergeTree适合所有的场景。
建表时不要使用Nullable,因为官方已经指出了,且这种类型几乎总是拖累性能,所以建议使用一个特殊字符来表空,比如-1, 字符串null等等
合适的划分分区和索引,分区是必须的,官方建议按天分区,建议自己分区的话单分区不超过100w行数据。
数据变更不要太频繁,避免产生过多的临时分区,加大合并的负担,如果要修改建议少次数,大批量的更新修改。官方建议1秒左右发起一起写入操作,单词操作写入数据量保持2w-5w ,具体根据服务器性能定
使用prewhere代替where,因为where是获取整行然后再过滤,而prewhere直接过滤列
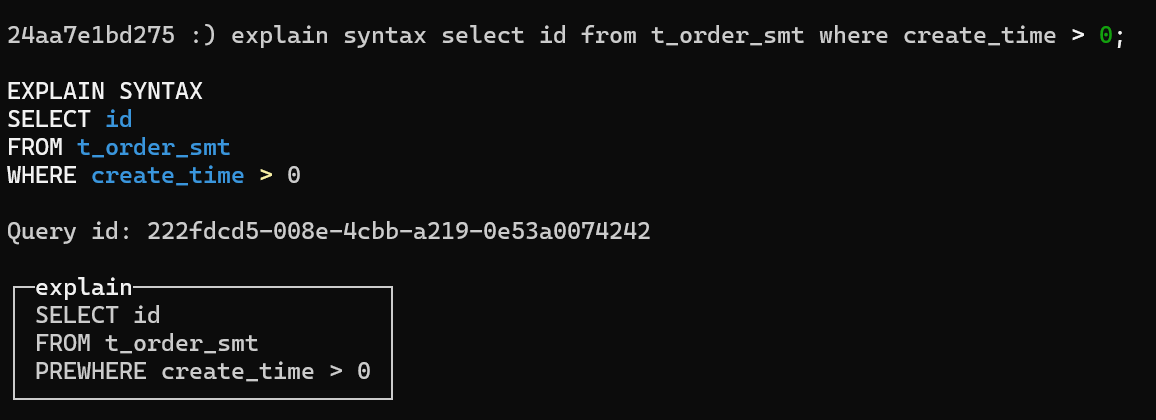
指定列和分区,避免select *, 减少内存消耗
避免构建虚拟列,减少内存消耗
比如:select income,age income/age as incrate from xxx
正例:避免虚拟列,直接写select income,age from xxx用in代替join
join会加载到内存,再计算消耗内存如果非要join,尽量把大表写在前面,小表写后面,这跟mysql 建议小表驱动大表相反。
生产常见问题
- 数据一致性问题
ch强调最终一致性,事务控制天生比较弱,主要源自于合并的机制,新分区合并到旧分区
分布式表尽量避免使用,要用就用副本表, 分布式表网络重试问题丢消息,副本同步机制,再次启动还会同步,更稳定可靠
数据合并时间不确定,不一致问题要注意, 可以定期夜间optimize final, 如果非要一致性,就用_sign _version 来标记自己用乐观锁机制保持一致性(sign标记是否删除,version标记新增)
多副本表,尽量固定写入节点。因为ch 副本是同权的, 如果随机写,一个挂了依然写成功了,但是数据不对齐了,固定写入一个节点,这样挂了立马可以知道
zookeeper数据丢失导致副本无法启动。
- 本文标题:Clickhouse总结
- 本文作者:形而上
- 创建时间:2024-01-10 21:01:00
- 本文链接:https://deepter.gitee.io/2024_01_10_clickhouse/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!